




Okay, so Claude Opus 4.8 is officially here. And honestly, every time one of these big AI models launches now, it feels like the AI race has entered a new level. Just when we think one company is slightly ahead, another one comes in with a new model, new benchmarks, better coding, better reasoning, better agents, better context, better everything.
This time, it is Anthropic with Claude Opus 4.8.
According to Anthropic, Claude Opus 4.8 is an upgrade over Claude Opus 4.7, with improvements across coding, agentic work, reasoning, knowledge tasks, computer use, and honesty. The pricing is also unchanged, which is good because these top-tier models are already expensive enough for heavy users.
The interesting part is how Claude Opus 4.8 is being positioned. This is not just “a better chatbot.”
This is clearly being pushed as a serious work model.
Something you can use for coding, software projects, large workflows, knowledge work, research, analysis, and even more agent-like tasks where the AI does not just answer one question and disappear, but actually works through a larger problem.
One of the biggest new features is reasoning effort control directly inside Claude.ai. Earlier, this kind of control was more of an API-side thing, but now users can choose how much effort Claude should put into a response from the website itself, which is pretty cool in my opinion.
Basically, if you want a faster response, you can keep the effort lower. If you want deeper thinking for a complex task, you can push it higher. Of course, higher effort also means more credit usage, so this is not exactly free magic.
Claude Code also gets more interesting with dynamic workflows, where Claude can work on larger tasks and even run parallel sub-agents for bigger coding problems. This is where I think AI coding tools are going next. This is like making the AI understand the entire project, plan the work, execute it, check it, and then report back.
That is a completely different level of software assistance.
Now coming to benchmarks.
Claude Opus 4.8 looks strong on paper.
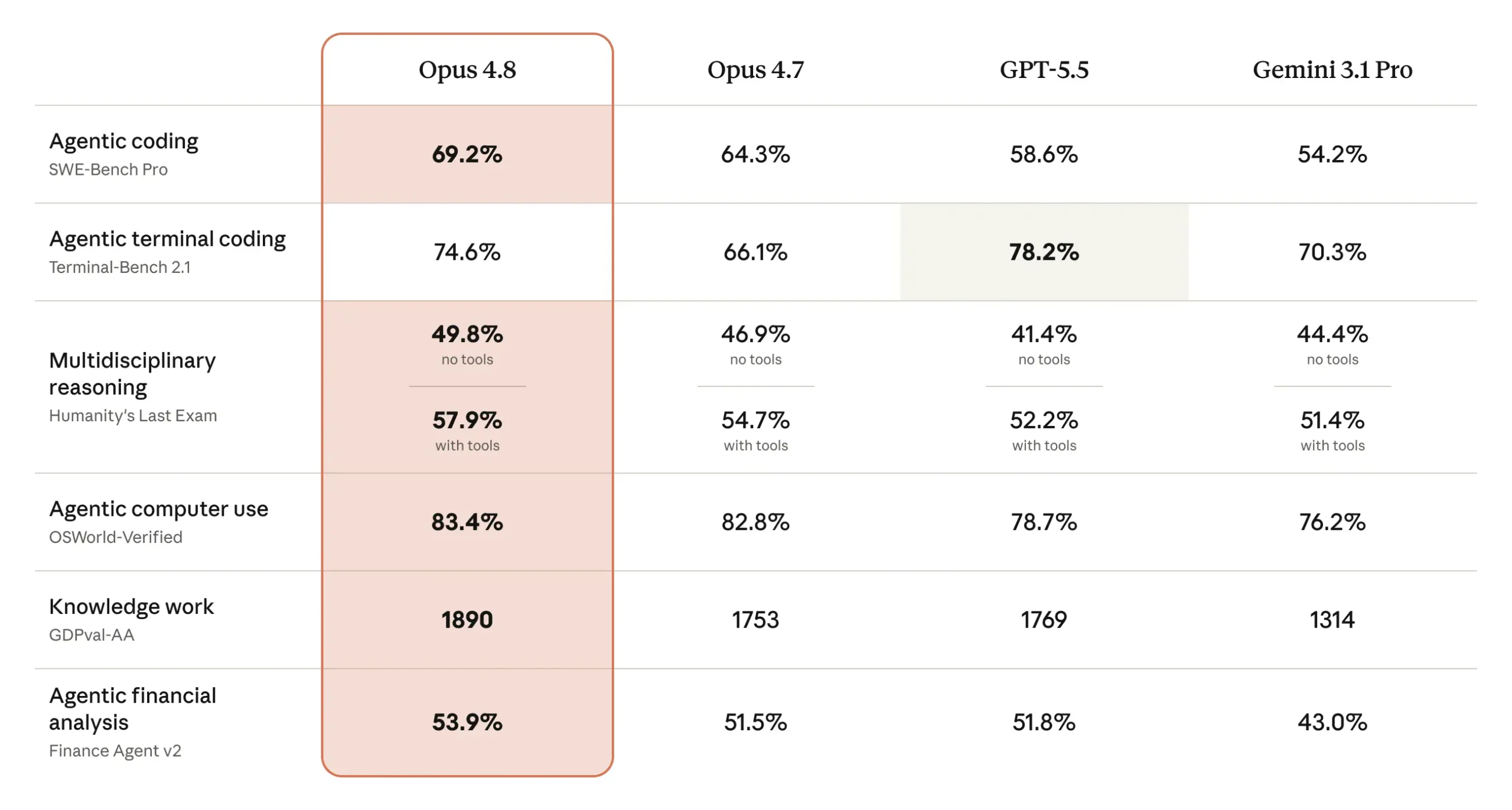
On SWE-Bench Pro, which focuses on agentic coding, Opus 4.8 scored 69.2%, compared to Opus 4.7 at 64.3%, GPT-5.5 at 58.6%, and Gemini 3.1 Pro at 54.2%.
That is not a solid jump, but hey, a jump is a jump on papers.
On Terminal-Bench 2.1, which is more about agentic terminal coding, GPT-5.5 is still ahead with 78.2%, while Opus 4.8 scored 74.6%. So this is not a clean “Claude beats everyone everywhere” kind of launch. It is more nuanced than that.
Claude wins in some areas, GPT still leads in some areas, and Gemini is also not sitting quietly.
On OSWorld-Verified, which tests agentic computer use, Opus 4.8 scored 83.4%, ahead of Opus 4.7, GPT-5.5, and Gemini 3.1 Pro. In knowledge work through GDPval-AA, Opus 4.8 also scored 1890, which is higher than GPT-5.5’s 1769 and Opus 4.7’s 1753.
So overall, the benchmarks are not too impressive, this is just like an incremental update to the previous model.
But here is the thing.
Benchmarks are benchmarks.
They are useful, but they are not the full story.
And this is exactly where Reddit reactions became interesting. A lot of Claude users are not simply celebrating the launch. Many are skeptical. Some users still seem to prefer Claude Opus 4.6 and feel that 4.7 was not a great experience for them. Some people are worried that 4.8 is more like a polished version of 4.7 rather than a true return to what they loved about 4.6.
There are also complaints around token usage, effort controls, and whether the model actually feels better in real-world work.
And honestly, I understand this. Because for people who use AI every day, benchmarks are not enough. But benchmarks are enough for marketing purposes.
The real question is:
Does it understand my instructions better?
Does it make fewer annoying mistakes?
Does it code better in my actual projects?
Does it remember context properly?
Does it push back when needed?
Does it hallucinate less?
Does it feel useful, or does it just sound smart?
That last one matters a lot.
One thing I do like about this launch is the focus on honesty. Anthropic is saying Opus 4.8 is better at admitting uncertainty and less likely to confidently pretend it has done something properly when it has not.
This is very important.
Because one of the most frustrating things about AI tools is not when they fail. Failure is understandable. The real problem is when they fail confidently.
They say the code is fixed when it is not.
They say they checked something when they clearly did not.
They give you a polished answer, but the foundation is weak.
So if Claude Opus 4.8 is genuinely better at being honest about uncertainty, that is a big improvement. Not just for casual users, but especially for developers, researchers, analysts, and teams that rely on AI inside serious workflows.
The hands-on demos also make it look quite powerful.
People are testing it with interactive web apps, simulations, dashboards, coding tasks, science lessons, and larger software workflows. In some tests, it seems to handle things better than 4.7, especially when the task needs planning, structure, and cleaner execution.
But again, we need more real-world testing before calling it a massive breakthrough.
For me, the bigger picture is this:
The AI race is becoming really awesome.
Anthropic launches Claude Opus 4.8.
Google is pushing Gemini heavily.
OpenAI is obviously not going to sit silently.
And I honestly would not be surprised if GPT gets a counter model soon, very soon.
I am not saying this is confirmed, because we do not know that. But based on how this race usually goes, every major model launch creates pressure on the others. One company raises the benchmark, another company responds, then another one comes back stronger.
And this is great for users. Because competition is what pushes these models forward.
Better coding.
Better reasoning.
Better agents.
Better pricing pressure.
Better reliability.
Better tools.
Better integrations.
A few years ago, we were amazed that AI could write a decent paragraph.
Now we are comparing models based on whether they can manage large software projects, reason through complex tasks, use tools, run workflows, and reduce hallucinations.
That is insane progress.
But one thing is clear. The AI race is not slowing down.
And honestly, I love watching it.
Anyway, that’s all I got regarding Opus 4.8.
Until next time, Stay strong and keep learning.
– Rocky




